当前的 AI 热潮从 22 年底 GPT3,即 OpenAI 发布 ChatGPT 开始。可以称得上热潮,因为它是真正“火出圈”了,连非技术人员、非圈内人也惊讶于它的效果,都在讨论它究竟有没有用、对自己的工作具体能起到多大作用、将来能走多远。也有自媒体就着这股讨论的新鲜劲发起了类似的作品,讨论智能、赛博朋克,讨论各种各样的技术以外的、甚至略带科幻性质的取代人类与否的话题。
其实 AI 早在 ChatGPT 以前就已经深度进入了我们的生活。我们会在使用到的当下很感激 AI 成功的应用,但是在使用过后往往就忘掉了,例如早已普及的无人停车场和车牌识别,这样的技术体验放在以前还是令人相当难以想象。再后来人脸识别也普及开来了,近到小区门禁,再到公司打卡,远到出门搭高铁乘车,还有办理银行、市政服务时都必须在手机上刷脸认证,我们渐渐对这样的技术应用习以为常,心里也不容易翻起什么波澜,反倒把这当做理所应当一般。
既然我们早已对 AI 应用习以为常,那为什么见到 ChatGPT 还是如此激动?大概是因为语言的属性。我们已经体验到的技术都是我们熟悉的工具和处理流程,输入输出我们都心知肚明,停车出场自然就是查车牌号、给钱,至于是人查的、还是人在电脑上查的、还是 AI 查的,都没有差异,只是效率有提升。人脸识别也是,当年没有 AI 的时候我们也过来了,即使没有人脸识别,我们也有其他手段来验证身份,无非就是效率低下一点而已,事情该做的还是得做、还是会做成。但我们确实没有遇到过由人以外的对象来给我们讲故事。我们渴望读到由人以外的对象给我们讲故事,在教科书上就有不少例子。概率书上往往会讲一个故事,如果有无数只猴子,他们都在敲击面前的键盘,那么总有一只猴子能够敲出莎士比亚全集来。大家都知道图灵测试,这也是 AI 的研究者们多年来苦心想攻克的里程碑。在科幻小说里也有一段相当著名的印象,我们总希望在某个时刻,能收到来自太空的、来自遥远的未知的一段信号,通过解析它,我们就能离宇宙的真相又进了一步。
LLM GPT 的出现开启了各行各业的人对未来的憧憬和希望,有人已经在工作中深度使用起来并且获益良多,行业中也已经早有提出了通用智能的概念,甚至有要模拟整个地球运作的构想。当然也有人对将来的 AI 看法相当保守,认为它有许多根本跨不过去的坎,持这样看法的人中不乏当今 AI 的引领者。对 AI 的看法显然是两极分化的,即便在同类的想法中也容易有各自的偏向、不易产生共鸣。自 ChatGPT 发布以来,我也有我自己的看法,在工作和生活中接触至今,有些看法有所改观,但核心想法更坚定了,于是现在我也想谈一谈。
AI 不是答案
我不认为 GPT 是答案,也不认为 AI 是答案。
正值巴黎奥运会即将开幕,就像奥林匹克格言 “更快、更高、更强” 所言,纵观人类发展的历史,我们人类所追求的、引起人类社会激烈变革的,从来都是 “更快、更高、更强”。火自然是更强了,能利用火的人类掌握了断层领先的能量供应;人类自己也一样,稳定的社会结构需要团结、需要人口、需要更强壮的个体,因为更强壮意味着能做更多事,意味着每单位的粮食消耗能带来更多的成果;马也是显然的更快更强,无论是社会上载货运输,还是军事上的移动和攻击,人类根本离不开马;一马力等于一匹马每分钟能够将33000英尺·磅力移动1英尺的功率,而经过蒸汽机、内燃机的发展,如今家庭只需工作不到一年时间就能拥有百匹马力,试问几百年前的人们如何能想象到?(截至2023年,中国城镇私营单位就业人员的年平均工资为68340元,一辆五菱宏光售价 4.3 万,马力 99 匹)飞机第一次成功试飞是人类历史的丰碑,人们一直渴望更高,但当时应该没有人敢想象能到这么高;而现如今,只需要不到一个月工资(同上数据),我们每人都能看着手里 249 克的小玩意儿飞上天。
我们渴望更快、更高、更强。我们希望走得远,但走得远谁都能最终到达,在更短的时间内走得更远才是我们追求的,也就是说,结果相对于耗费的梯度要尽量大,这是我们所真正追求的。
回过头来,我们先看看 AI 的原理。现今 AI 浪潮的两个爆炸式的奇点,一是 AlexNet 和 ImageNet,二是 ChatGPT,它们都是利用梯度下降,在大量数据的训练下的某种组织形式下的权重数值。梯度下降方法给予了人类一种能力,在无限的数据下,只要能规定好某个目标,就能在数据中朝着这个目标一直前进、尽量达到。如果要认识一只猫,那就不断地给模型数据就好,好的数据教会模型什么是猫,坏的数据教会模型什么不是猫,只要数据够多,反正人类终其一生能看到的猫也是有限的,那模型能逼近的极限也就接近人类的极限,尽管模型不一定是按照人类的方法学会的,尽管我们永远都不知道模型所学会的是不是人类脑海里的那只“猫”,尽管可能模型接收到人脑所接收到的信号就可能认不出来了,但无所谓,我们人类认为是猫的数据给到模型,它也说是;我们人类说不是的,模型也说不是;甚至人类出错时,模型还能正确,那么我们就可以认为,在给定的这种数据形式下,模型对“猫”的判断是可信的,我们把这种认知简化地、夸张得甚至有点不负责任地称为:模型具备了能识别猫的智能。
GPT 的原理是一样的。作为语言模型的一种,GPT 也不例外的只负责完成一件事情:根据已有的词推测下一个词是什么,推测的词又再作为已知的词,循环往复不断生成,仅此而已。GPT-3 如此瞩目,是因为它的表现大大超出了人们的预想。
GPT 的成功得益于它内部的真正功臣 Transformer,这是一种特殊的结构,它的特殊之处在于,在它之前的其他结构(其他语言模型),没办法有效的“学习”(梯度下降)大量的数据,一直喂数据,增益就一直打折扣,最后就消失了,意味着模型只能学习有限的数据。只能学习有限数据的 AI 模型没有意义,因为它永无提高的空间了。而 Transformer,可以一直往里输入数据却没有任何学习的衰减,如下图,模型越大,性能越好,一直增大到 GPT-3(ChatGPT,一千多快两千亿的参数量!)也没有看到尽头。注意看左图,随着线性增加的模型大小,模型性能 log 级下降,反过来就是模型性能是大小的幂次(power law)。巧了,摩尔定律也是 Power Law,CPU 的性能每两年翻一倍,晶体管数量按指数级上升、成本指数级下降。Transformer,仿佛就是 GPT 体内的晶体管。
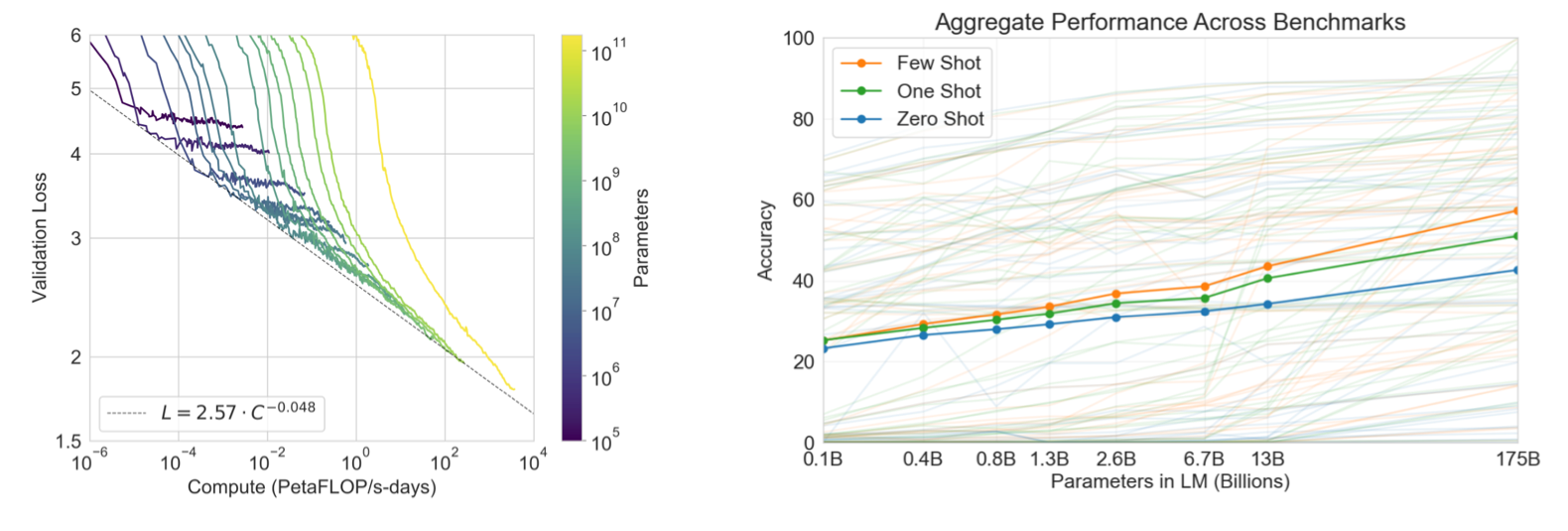 |
| language models are few shot learners, 2020 |
一直堆资源,一直投入,GPT 就能给出越来越好的结果,直到从 GPT-3 开始,人们看到了他们想要的那种输出,这就是 GPT 的故事。不管 Transformer 多么有效,GPT 也仍然是 AI 的一种, 梯度下降的本质始终没有改变。AI 都是对数据进行有效的提炼。
那 GPT 让人类更快、更高、更强了吗?它没有让人类的钢铁硬度更高,没有让一箱油更耐烧,也没有让人思考的更快。车牌识别、人脸识别,把原来一个耗时的识别过程,大大压缩了时间,高效地输出了可靠的成果,因此是更强了。那语言模型 GPT 呢?它给我们带来额外的知识了吗?没有,因为它只是对输入数据的提炼,但提炼却不会带来新的、原来不存在的信息。
GPT 只是能输出一段自然流畅的话,话里倾向于(至少或多或少)会包含有贴近用户提示词的内容,但他既不保证准确,也不保证合理,即使保证准确、合理那也不是 GPT 的功劳(而是在 AI 的结果之上,工程人员使用非 AI 的方法来加强内容的准确性和合理性)。他也不保证出乎意料,无法输出世上没有说过的话。
涌现
涌现是大语言模型为人所津津乐道的一种能力。事实上不局限于大语言模型,任何所谓复杂系统,任何自以为聪明的人都无法立刻掌握的那种系统,更典型但不限于的例如包含了很多偏微分过程的混沌系统,都可能存在涌现的现象,它是指,虽然基本组成部分是如此简单、可预测,但一旦组成了复杂系统,就出现了另外一些乍看之下难以推导、关联的更多的属性和特点。举几个例子。每个人生下来都会玩水,都知道水流起来是什么模样,但如果告诉大家,如果水按照某种方式来流动,就形成了卡门涡街,可能就会有人把它称为是复杂流体的涌现现象。类似的,在泰国有一种萤火虫,它们会忽然在同一瞬间同时点亮,照亮整个夜晚的森林,然后又回归到各自闪烁,但过一段时间又会重复同时点亮,这是为什么?这仅仅是因为,每一个萤火虫个体,在看到附近的同伴亮起之后,把自己的闪烁的时钟提前一些,仅此而已。GPT 为人所津津乐道的涌现能力,指的是当模型达到一定规模时,性能显著提升,并展现出意料之外的能力,如语言理解、生成、逻辑推理等,但果真是这样吗?
所谓涌现,专指复杂系统,所谓复杂,就是难以理解。基本要素我们都能搞懂,但是组合起来,依然让人难以想象,所以我们把组合后的、复杂的、难以理解的结果称为涌现,仿佛那是复杂本身所带来的额外价值。不,那只是说明了我们的无知和惊讶而已。认为复杂系统忽然就获得了特别的能力,恰恰只反映了我们人类对于未知的惊讶,就像对于原始产生的自然崇拜一般,认为有种未知的力量为我们带来了额外的成果,但这些“涌现”的能力实际上没有本体,本体始终只有基础原理、基本组件,以及组合本身,它们是这样工作,是这样组合,那么就会有这样的结果,不需要造一个名为“涌现”的词再去画蛇添足的描绘它,那是它本来就带有的属性。我们把这些所谓高级属性、能力称作涌现,除了表达惊讶以外,没有再增添任何价值。
之所以认为 GPT-3 具备涌现能力,正是因为 Transformer 是有效的,遵循规模性能 Power Law,直到这个版本,因为他足够有效,因此我们满意这样的输出,所以凸显出了它跟之前的版本的效果提升。
我还想更进一步解释,为什么有时候 GPT 给出的回答看着那么像一回事?我们通常认为情感是人类独有的,而语言能反映人类情感,快乐、悲伤时的用语都会有差异,特别的,诙谐的语言往往让人眼前一亮,这样的内容我们倾向于认为是人类能信手拈来,而机器即使费九牛二虎之力也难以做得自然的。但 GPT 如今已经能轻松生成这类文字了。但我不认为这说明 GPT 已经具备了察言观色的能力。正如无数只猴子也总有能敲出莎士比亚的,刚好敲出莎士比亚的那只,我们能说它有一定的文学素养吗?GPT 是用人类实际的语料训练的,自然就带有了日常语言的特征,如果平常大量人类文本有类似的语言氛围,GPT 又精于自然流畅,当然可以生成大量的类似文本,它能“观色”,是大量的训练数据在“察言”。即使 GPT 输出了一段诙谐灵动的话,那也只是文本如此,因为世上已经有人这样说过了,至于读者感到诙谐灵动,那是他自己读到这段话之后加上去的主观情绪,于是误以为是写者 GPT 带着同样的情绪所写。
说到底,GPT 给出的回答看着很像那么一回事,是因为我们人类对这种文字的感觉自然,我们就认为语言该这样,凡是这样的文字我们都觉得像一回事,是“我们” + “文字” 构成了这“一回事”,这里面 GPT 除了负责生成以外,对于是不是一回事,不太关心,真正关心的、真正促成这“一回事”的,是训练 GPT 的工程人员,是负责清洗构成数据和训练的 AI 人员。使用人类自然语言训练出来的 GPT,给出的回答看着像一回事,是它的应有之义,是 AI 梯度下降应该有的效果。
那 GPT 学习到数据蕴含的知识、并且能运用了吗?最近 GPT 回答 “3.11 比 3.9 大” 的新闻想必大家已经知道了,不说运用,单单是学,也没能学会。
所以说,称赞 GPT 具备涌现能力,很大部分是反过来反映了人们的惊讶、惊喜,反映了 GPT 的有效和流畅,反映了人类文本训练数据内部隐含的一致性。正是我们的快乐之所谓是快乐,悲伤之所以是悲伤,诙谐之所以为诙谐,GPT Transformer 才能用梯度下降学到手,我们就仿佛在照镜子,看到的都是我们自己。因此,不必惊讶,我们应该要比 GPT 自己还要更习以为常。
别急着夸
我倾向于相信,世上没有救世主。没有什么技术能替代这替代那的把人类工作全部包揽了,如果存在,那我也好奇这万能药的代价是什么。
如前所述,GPT 最擅长的,是让输出的话语读起来流畅、看上去自然。文字自然流畅是重要的,但若言之无物,流畅毫无意义。有人可能会提出异议,说最近用的 AI 还挺好用的,还能利用实时搜索返回有用信息,但我认为,有用的信息恰恰是因为搜索、而不是 GPT,我们仅用搜索工具,也能拿到有用的结果。说到底,GPT 对大段文本的归纳,就是将一本书用几段话概括的本领,应该是它最有效的使用场景了,但文学小说最能打动我们的,恰恰是那些被概括掩埋的细节;议论说明的脉络,不需要概括我们也能速读出来,而论点的有效性恰恰需要在逐句的议论中体现。
GPT 能概括、能提炼、能聊天,能有效表示文本,因此可以利用 embedding 构造专项的数据库和相似性搜索,换言之,它类似于语言的有效的压缩器和放大器。在这之外,目前看到的应用里,都需要更多的东西才能满足大家的需要。
GPT 所真正替代的,可能只是人类的阅读、思考和表达的能力,它给我们节约了多少时间,就削弱了我们多少,不禁没有帮助我们“更快、更高、更强”,仿佛给我们的是“更少,更弱,更懒”。语言是思维的延伸,我们要的是思维,但如果都只满足于语言,那么语言除了是字以外还是什么?我们要的是创意、新闻、变化,是能让生活变得更好的高熵的信息,但把人类已有的文本揉碎了又吐出来的低熵 GPT 结果给不了我们多少。如果说本轮 GPT 狂潮是有益的,那么相当于说我们更在意流畅而不在意真实(we favor eloquence over truth)
AI GPT 没有开辟新的赛道、新的战场、新的领域,一切技术都是原已有的。AI 还是熟悉的方法,结构还是 17 年的发明,著名作家诗人的名单没有被新来者淹没,数学难题的解、新程序也没有因为爆发生成导致存都存不下,人们还是在做他们一直以来的工作,只是多了一个工具而已。反而 GPT 更进一步加剧了富集、孤岛、分裂和虚假。原来已经掌握了我们数据的巨头渴望更多,原来已不想开放数据的 APP 更急着隔离,原来已经引起重视的计算资源更加捉襟见肘,原来已经充斥的虚假信息愈演愈烈,虚假信息带来的不信任和动荡随之加剧。
在看到 GPT 的优点之前,我已经被许多不安淹没。
资本有效
任何东西都能聊出缺点来,但不妨碍它能发展与否。优缺点和发展是正交的维度。当年 ofo 刚出来的时候,我还立马吐槽这随地停车给城市带来的成本呢,事实证明,没人在乎。
新冠疫情从 20 年到 22 年;美国本轮加息从 22 年 4 月持续到 23 年 8 月并维持至今;俄乌战争在 22 年 2 月开始;国际金价从 22 年 10 月开始持续走高,只在 23 年底有过一次 swing;中国房市,恒大危机在 21 年开始;美股科技 ETF 在 22 年 1 月开始持续向下,在 22 年底几乎回到了 20 年甚至更以前的水平。近年来摩尔定律也被认为开始失效。
世界局势紧张,金融市场动荡。互联网、移动设备、直播等互联网服务都增长得差不多了,站在 22 年的多事之秋,如果你是手握重款的投资经理,你会把钱投向何处?恰逢此时 22 年 11 月底 ChatGPT 横空出世火出圈,你会不会投?如果你知道摩尔定律,然后又了解到了 Transformer 也遵循规模性能 Power Law,你会不会投?不管会不会,已经有大量资源已经投入了,才有 ChatGPT(GPT-3)的诞生。
其实不只是资本,不只是金融,所有资源,包括人的努力,都希望投在既确定、又有回报的事物上,毕竟,一直努力一直就能有成果,这样的事实谁不向往呢?而眼前确定的事物不多了而且越来越少,有回报的事物也不多了而且也越来越少,剩下的又缺少足够的成果。从短期看,22 年底 ChatGPT 发布并且受到资本和市场追逐和热捧,占尽了天时地利。把时间拉长一些,Transformer 诞生于 17 年的 Google,而同期比尔盖茨已经与 OpenAI 建立起了联系。在 23 年 OpenAI 管理动荡之际,也是 MS 出手稳定住了局面。掌握了资源和知识的人们已经合作在上面深耕多年,在如今迎来枝繁叶茂的成果,为大家畅想美好的未来,也正是价值兑现的应有之义。更不要说还有 GPU 这个半导体 + 可规模化设计的吸金怪兽,这可是真真正正的“更快,更高,更强”,核效率、访存 bus 速度都构成了坚实的计算基础。
在 GPT 上作投资,既有 Transformer 确定性的性能增长,又能拉动半导体的既定产业,又能把巨头们手上的数据再利用、深化利用,进而再增大规模、拓宽护城河、掌握新产生的数据,形成规模增长闭环,还能通过生成式内容在社交媒体和互联网服务上掌握主动权,向内容创作者收“媒体生产税”,向政治收广告费,提高 UGC 参与者所缴纳的“地租”,这对于掌握互联网生产资料的人来说,不恰恰就是“更快,更高,更强”的事吗?
我比较同意一个来自于中国工程院院士王坚的不等式:AI 应用 < 基础模型 < 算力 <电力,意思是每一级生态都没有完全用尽上一级所提供的全部资源,所以还谈不上什么瓶颈。因此在全链路可规模化的行业生态下,这个方向是持续可发展的。
光明存在于阴影之上
说完第一时间的批评,结合信息作了第二时间的理解,最后终于到了表达当下结论的时候。
GPT 虽然做不到很多我们渴望它能做的东西,但它也能完成很了不起的事情。毕竟,AI 本身就非常了不起。正如车牌识别、人脸识别那样,对文本作归纳,并用自然语言回复,还能带上形象的语气,甚至还能用于进一步的细致的文本语料处理,这都是实打实的成果。
相比起 CV 领域那么多年那么多成果引人瞩目,语言领域似乎相较之下比较默默无闻。但视觉图像、视频跟语言有本质的不同,人是无法凭空拿出一张照片来的,但语言几乎是我们与生俱来的。我们通过语言能直接表达自己、跟外部交流,但通过眼睛,我们只能被动地认识世界的模样。GPT 是 AI 真正征服语言的里程碑,意义无可比拟,它真正给予了机器与人类需求的平等沟通的能力。
不可否认,人类的工作,并不时时刻刻都在创造、都在思考,人类还仍然被很多无趣、重复、单调的工作困扰着,而 GPT 能把人从这些工作中释放出来。它为我们打开了一副枷锁,我们应该感谢它。
也有很多信息只是庞杂,但显重复,人们的经验总是容易局限于他自己熟悉的那方面、那领域、那些有着同样历史的过程,领域的迁移所带来的庞杂信息的处理成本,是我们难以承受的,而 GPT 恰好能帮到我们。不熟悉一个新的领域,不知道新的术语、关系结构,甚至该问什么问题都拿不准,先问问 AI,或许这些烦恼都不存在了。
GPT 还能用来激发创意,连陶哲轩都鼓励数学学术界并分享自己使用 GPT 的心得和思路。诚然如我前面所说,语言是思维的延伸,我们要的是思维,不应只满足于语言;但正是因为我们是思考的主体,GPT 给的信息,恰好是我们的新起点,既能帮助我们查缺补漏,又能帮助跨领域快速上手,还能手把手地教我们做些简单的工作,我们的思考和创意不再需要背负沉重的劳力负担,得以更加轻装上阵。
虽说我不赞成过度渲染 GPT “获得”了什么涌现能力,但生成式 AI 的这种 “结果恰好符合人类主观解释” 的 “理性照镜子” 的特点,颇有些 “Fake it until you make it” 的浪漫气息。
全人类的智慧得以汇聚,通过 GPT 这个管道,投影到每个人的脑海里。我们每个人脑海里的坐标系是怎样,就能得到怎样的影子(或者向量),说白了,如何发挥工具的价值正取决于使用者不是吗。
知道在哪里容易摔倒,这条路我们会走的更加轻松,至于要不要往前走,不是我们应该浪费时间去考虑的问题,既然已经在路上,那么我们来想想要去往何方。